Optical Character Recognition, better known as OCR, is a method of converting a file into text. This file could be a scanned copy in a PDF format or just an image you take with your phone. Google took on the personal OCR ability in June 2010 for five different languages, but now has support for 34 different languages. The system allows you to upload a PDF or image file into Google Docs in addition to converting other documents, like Microsoft documents, into the Google Docs format.
Uploading these files will allow you to easily take a formatted document and convert it into a editable Google Doc. The system will do its best in preserving the formatting, text size and alignment of the document. No system is perfect, but Google is constantly upgrading the quality of the OCR converter.
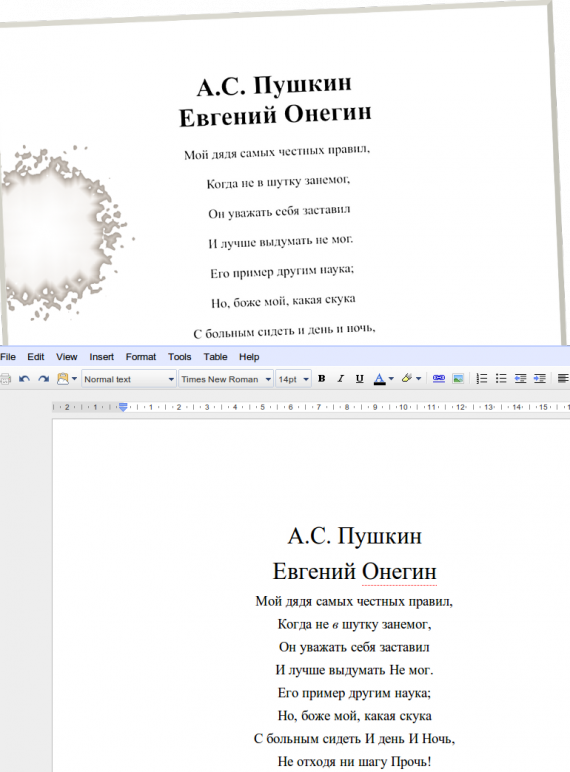
Don’t have the time to convert that 10 page homework assignment into a PDF so you can type out the answers? Save the time and let Google OCR do it in one of the following 34 different languages:
- Bulgarian
- Catalan
- Chinese (Simplified Han)
- Croatian
- Czech
- Danish
- Dutch
- English
- Filipino
- Finnish
- French
- German
- Greek
- Hungarian
- Indonesian
- Italian
- Japanese
- Korean
- Latvian
- Lithuanian
- Norwegian
- Polish
- Portuguese
- Romanian
- Russian
- Serbian
- Slovak
- Slovenian
- Spanish
- Swedish
- Thai
- Turkish
- Ukrainian
- Vietnamese



{kind=link}